Text and data mining (TDM) is the automatic analysis and extraction of information from large numbers of documents. Researchers are increasingly interested performing text and data mining on scholarly content. This requires automated access to the full-text content of large numbers of articles. Crossref metadata helps researchers get access to this content and enables publishers to provide it.
Crossref Metadata
Crossref maintains the database of DOIs for its 4000+ publisher members. Every DOI has bibliographic metadata associated with it, describing various pieces of information about a piece of content, be that a journal article, book chapter or conference proceeding. The metadata deposited can be expanded to identify where the full text of a piece of content can be found, and this information can then be used by researchers interested in text and data mining.
A Common System for Publishers and Researchers
Researchers are increasingly interested in text and data mining published scholarly content. This poses technical and logistical problems for scholarly researchers and publishers alike. It is impractical for researchers to negotiate multiple bilateral agreements with subscription-based publishers in order to get authorisation to text and data mine subscribed content, and negotiating those same agreements with large numbers of researchers takes time and effort on the part of the publisher. In short, all parties would benefit from support of standard APIs and data representations in order to enable text and data mining across both open access and subscription-based publishers.
What does Crossref Provide?
The main component of Crossref’s text and data mining services is a Crossref Metadata API that can be used by researchers to access the full text of content identified by Crossref DOIs across publisher sites and regardless of their business model. This will be free to use by researchers and the public.
The Crossref Metadata API has three basic sub-components:
- A common mechanism for providing automated text and data mining tools with direct links to full text on the publisher’s site
- A common mechanism for recording license information in Crossref metadata
- An optional common mechanism for rate-limiting automated text and data mining tools using HTTP headers
Why is this necessary?
In the past, researchers who wish to text and data mine published literature have no common or simple way of accessing the full text for the content they wish to mine. This is true both of subscription-based content as well as of open access content. Consequently, text and data mining users access the content in one or two ways:
- Negotiating with publishers to have the content delivered to them, either via physical media or bulk data transfer (e.g. FTP)
- “Screen-scraping” the publisher’s website.
The first option doesn’t scale well across multiple Publishers and Researchers. It also presents synchronisation problems if the researchers want an ongoing feed of refreshed content.
The issue with the second option is that “screen scraping” is an inefficient, fragile and error prone mechanism for identifying and downloading full text. Screen scrapers put a large performance burden on web sites and, at the same time, any slight changes to the web site can break the tool that is doing the screen scraping.
Crossref text and data mining provides a common solution which works across open access and subscription-based publishers and is free for anyone to use.
How does it work?
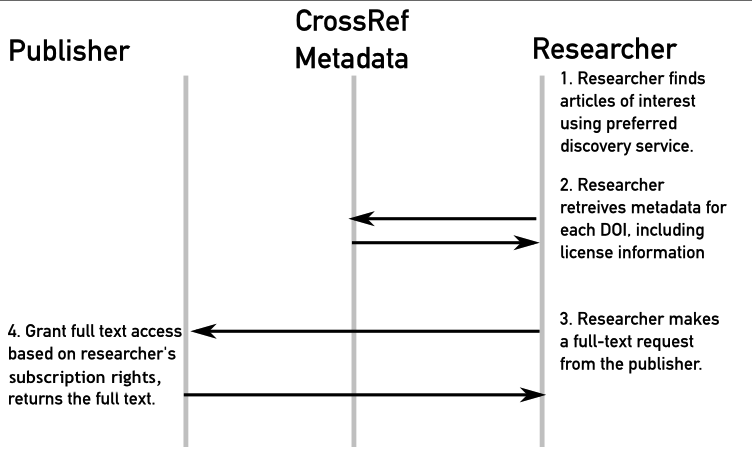
More information:
- If you’re interested in a basic run-through of how the service works from the researcher-side, you can view a short walk-through here (or download the .mp4 file here).
- Read the FAQs for Publishers or Researchers
Comments
0 comments
Please sign in to leave a comment.